Deep Reinforcement Learning from Human Preferences (2017 NeurIPS)
Website
https://openai.com/research/learning-from-human-preferences
Problem
Reward functions for complex tasks are hard to design
Solution
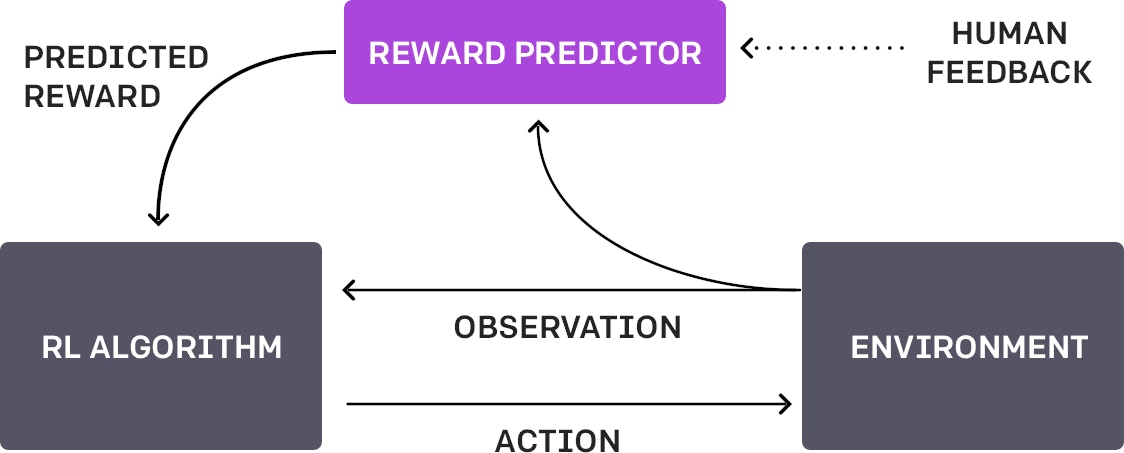
human preference data → reward model(NN)
“Our algorithm fits a reward function to the human’s preferences while simultaneously training a policy to optimize the current predicted reward function”
- The policy π interacts with the environment to produce a set of trajectories {τ 1, . . . , τ i}. The parameters of π are updated by a traditional reinforcement learning algorithm, in order to maximize the sum of the predicted rewards rt = ˆr(ot, at).
- We select pairs of segments (σ1, σ2) from the trajectories {τ 1, . . . , τ i} produced in step 1, and send them to a human for comparison.
- The parameters of the mapping ˆr are optimized via supervised learning to fit the comparisons collected from the human so far.
- Repeat
注意⚠️:reward是continuous value,因为它只是一个predictor,probability是reward套一个softmax得出来的,而非预测完probability之后,用0或1作为reward
Contributions
scale human feedback up to deep reinforcement learning and to learn much more complex behaviors.
Weaknesses
- 高昂人力成本
- 没有利用好score的力量
Experiment
Env: MuJoCo and Atari game
Comparison Experiment:
- Human queries: 人来标注数据
- Synthetic Oracle:when the agent queries for a comparison, instead of sending the query to a human, we immediately reply by indicating a preference for whichever trajectory segment actually receives a higher reward in the underlying task
- Real Reward
Ablation Experiment:
- Offline queries(train on queries only gathered at the beginning of training, rather than gathered throughout training) performs bad. Online queries are important for learning
- Comparison is easier to do for humans but
Findings
- human通过comparison标注数据的原因是it much easier for humans to provide consistent comparisons than consistent absolute scores
-
For continuous control tasks we found that predicting comparisons worked much better than predicting scores. This is likely because the scale of rewards varies substantially and this complicates the regression problem, which is smoothed significantly when we only need to predict comparisons.
注意⚠️:是predict不是label
Deeper?
- Binary comparison只能提供2选1的信息,relative magnitude of the reward are important to learning
- How to accelerate the learning and reduce the time of human labeling